

Google Apps Script(GAS)とOpenAI APIだけで、社内ドキュメントを検索・回答するRAGボットを自作します。ベクトルDBや有料サービスは不要。Chatworkに質問を投げるだけで、Google Drive内の資料をもとにAIが回答を返す仕組みを、コピペで動くコード付きで解説します。
目次
この記事でできること
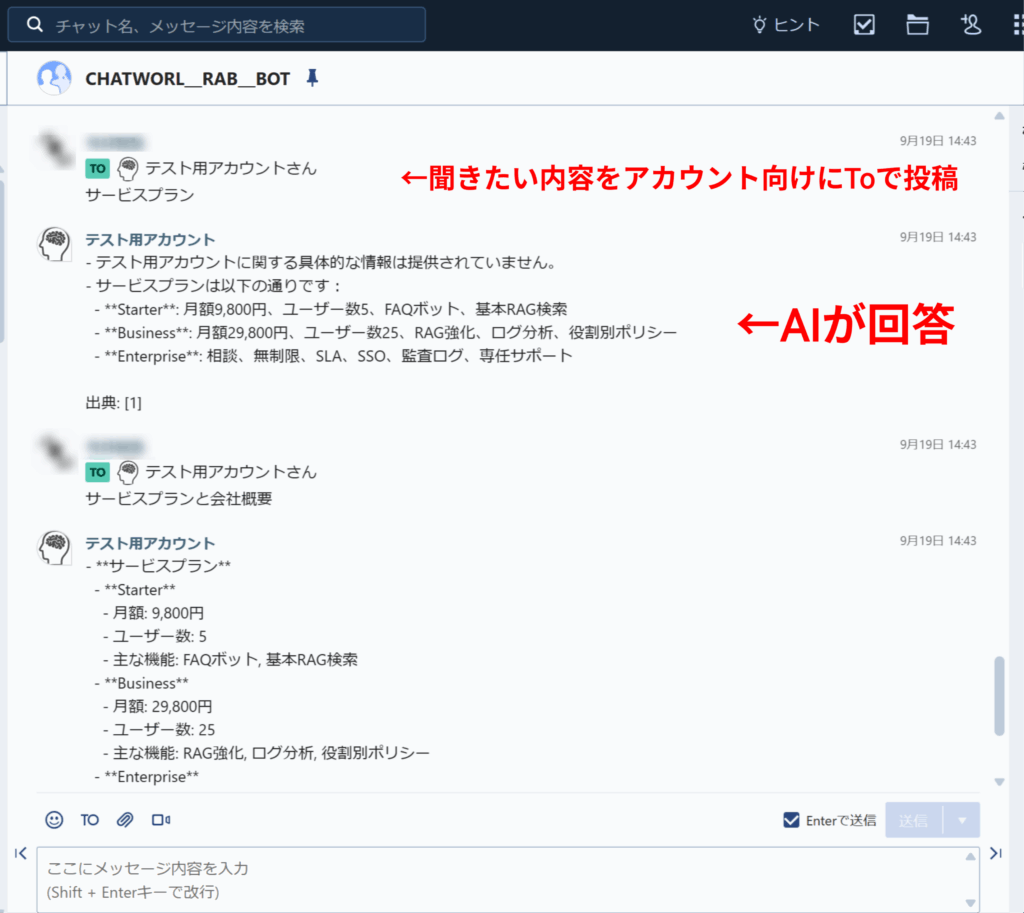
- ChatWorkで
[To:ボット] 質問文を送ると、Google Drive の資料をRAG検索して即返信。 - To付きのみ反応/連投防止/自己ループ防止を満たした、軽量な最小構成。
- 依存:GAS(Apps Script), OpenAI API, Google Drive/Spreadsheet。
全体像(アーキテクチャ)
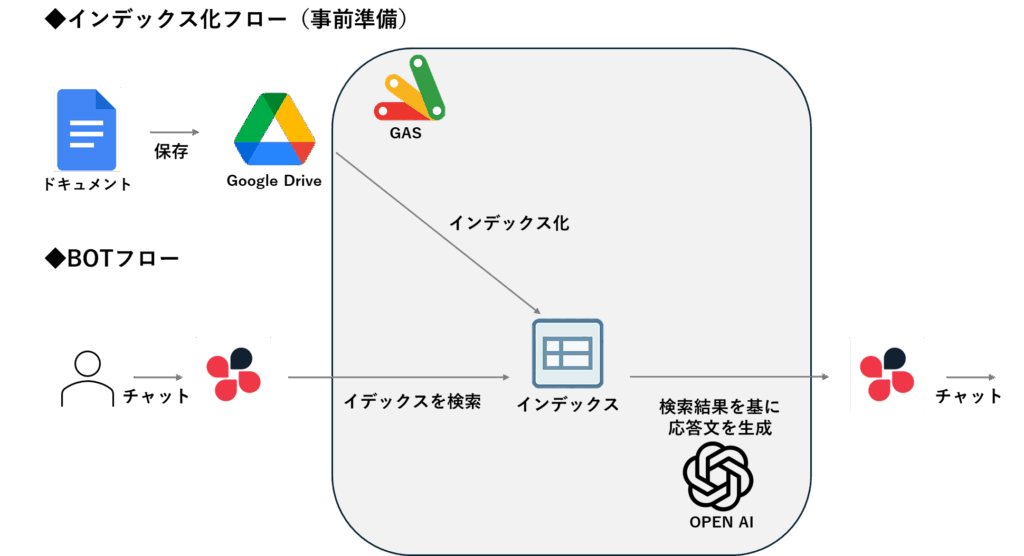
- ChatWork(メンション)→ Webhook(GAS
doPost) - 受信バリデーション(To判定/自己ループ防止/重複ガード)
- RAG処理:
embed → searchTopK → generate - ChatWork APIで回答を投稿
Webhookは同期で処理しています。後で負荷が上がったら「即200 ACK → キュー → 後送」の非同期化に発展させればOKです(本記事のコードは現行の同期版をそのまま掲載)。
この構成を選ぶ理由
- 無料インフラ:GAS+Google Drive+Spreadsheetで完結(OpenAI APIの従量課金のみ)
- 導入が簡単:コードをコピペしてScript Propertiesを設定するだけ
- 社内ツール連携:Chatworkから直接使えるので、新しいツールの学習コストゼロ
事前準備(チェックリスト)
Script Properties(必須)
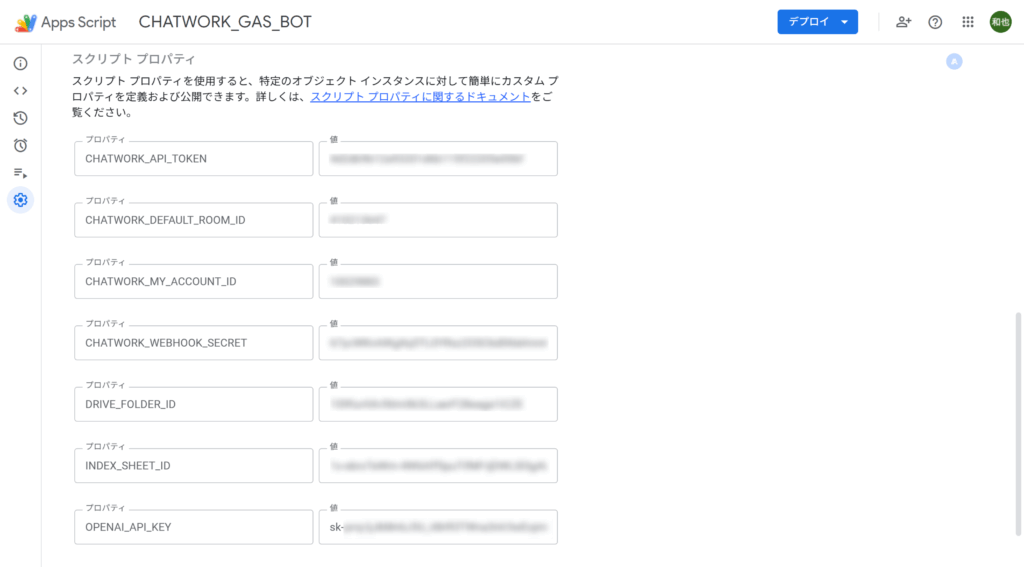
CHATWORK_API_TOKEN(BOT投稿に使うトークン)CHATWORK_DEFAULT_ROOM_ID(既定返信先ルームID)CHATWORK_MY_ACCOUNT_ID(BOT自身のaccount_id:自己ループ防止に使用)CHATWORK_WEBHOOK_SECRET(Webhookの「トークン」:署名検証に使用)OPENAI_API_KEY(OpenAIのAPIキー)DRIVE_FOLDER_ID(取り込みフォルダID)INDEX_SHEET_ID(インデックス保存用スプレッドシートID)
重要:プロジェクト内のどこかで
const PROP = PropertiesService.getScriptProperties();を宣言してください。
GAS / GCP
- Webアプリとしてデプロイ(実行=自分/アクセス=全員)→ 発行URLを ChatWork の Webhook に設定
- Advanced Google Services で Drive API v2 を有効化(GCP側でも有効化)
使い方(最短)— 改訂版
- コード①・コード② を同一GASプロジェクトに貼り付け(改変なし)
- Script Properties を設定(
CHATWORK_*,OPENAI_API_KEY,DRIVE_FOLDER_ID,INDEX_SHEET_IDなど) - ドライブにドキュメントを配置(
DRIVE_FOLDER_ID配下) - インデックス作成:GASから
buildIndexFromDrive()を実行(初回は必須/更新時は再実行) - Webアプリとしてデプロイ → 発行URLを ChatWork の Webhook に登録
- ChatWorkで
[To:BOT] 〜〜?と送信 → RAGの回答が返る
ヘルスチェック:
testIndexSheet()を実行するとindexシートの行数がログに出ます。OpenAI疎通はtestOpenAI()/testEmbedding()で確認できます(※コードは記事内の”コード②”に掲載済み。改変不要)。
コード①:ChatWork Webhook〜返信まで(改変禁止・テスト関数なし)
そのまま貼り付けて使えます。RAG本体はこの後の「コード②」を併用します。
// ===== ChatWork 用 設定(Script Properties にセット) =====
// CHATWORK_API_TOKEN : 個人トークン
// CHATWORK_DEFAULT_ROOM_ID : 返信先の既定Room ID(数値)
// CHATWORK_WEBHOOK_SECRET : Webhook編集画面に表示の「トークン」(署名検証に使用)
const CW_BASE = 'https://api.chatwork.com/v2';
function sendChatworkMessage_(roomId, text) {
const token = PROP.getProperty('CHATWORK_API_TOKEN');
if (!token) throw new Error('CHATWORK_API_TOKEN 未設定');
const url = `${CW_BASE}/rooms/${encodeURIComponent(roomId)}/messages`;
const res = UrlFetchApp.fetch(url, {
method: 'post',
headers: { 'X-ChatWorkToken': token },
payload: { body: text }, // ← form-encoded
muteHttpExceptions: true
});
const code = res.getResponseCode();
if (code >= 400) throw new Error(`ChatWork POST error ${code}: ${res.getContentText()}`);
return JSON.parse(res.getContentText());
}
// ChatWork Webhook 署名検証(HMAC-SHA256 + Base64)
// x-chatworkwebhooksignature ヘッダ、または chatwork_webhook_signature パラメータを検証
function verifyChatworkSignature_(e, rawBody) {
const secret = PROP.getProperty('CHATWORK_WEBHOOK_SECRET');
if (!secret) throw new Error('CHATWORK_WEBHOOK_SECRET 未設定');
const paramSig = (e?.parameter?.chatwork_webhook_signature || '').trim();
if (paramSig) {
const secretBytes = Utilities.base64Decode(secret);
const hmac = Utilities.computeHmacSha256Signature(rawBody, secretBytes);
const ours = Utilities.base64Encode(hmac);
return ours === paramSig;
}
// GAS からはヘッダが取れないため、署名がパラメータに来ない場合は一旦許可
Logger.log('Signature not present as query param; skip verification TEMPORARILY');
return true;
}
// --- 重複処理ガード(10分キャッシュ) ---
function alreadyHandled_(messageId) {
if (!messageId) return false;
const cache = CacheService.getScriptCache();
const key = 'cw_msg_' + String(messageId);
const hit = cache.get(key);
if (hit) return true; // 既に処理済み
cache.put(key, '1', 600); // 10分間だけ記録
return false;
}
// --- 自分の発言は無視(プロパティ未設定ならスキップ) ---
function isSelfMessage_(ev) {
const myId = Number(PROP.getProperty('CHATWORK_MY_ACCOUNT_ID') || 0);
const senderId = Number(ev.account_id || 0);
return myId && senderId === myId;
}
// --- To:自分 が含まれるかの判定(プロパティ未設定なら false) ---
function hasToMe_(body) {
const myId = Number(PROP.getProperty('CHATWORK_MY_ACCOUNT_ID') || 0);
if (!myId) return false;
return new RegExp(String.raw`\[To:${myId}\]`).test(body || '');
}
// ===== 基本動作 =====
function doPost(e) {
try {
const raw = e?.postData?.contents || '';
let payload = {};
try { payload = JSON.parse(raw); } catch (_) {}
const type = payload.webhook_event_type;
const ev = payload.webhook_event || {};
const roomId = String(ev.room_id || PROP.getProperty('CHATWORK_DEFAULT_ROOM_ID') || '');
// --- ここから最小追加 ---
// To付きだけ反応(mention_to_me も許可)。それ以外は無視。
const bodyRaw = ev.body || '';
if (!(type === 'mention_to_me' || hasToMe_(bodyRaw))) {
return ContentService.createTextOutput('ok').setMimeType(ContentService.MimeType.TEXT);
}
// 自分の発言は無視(プロパティ未設定ならスキップ)
if (isSelfMessage_(ev)) {
return ContentService.createTextOutput('ok').setMimeType(ContentService.MimeType.TEXT);
}
// 同一メッセージの多重処理を防止
const mid = ev.message_id || ev.id || '';
if (alreadyHandled_(mid)) {
return ContentService.createTextOutput('ok').setMimeType(ContentService.MimeType.TEXT);
}
if (type === 'message_created' || type === 'mention_to_me') {
const userText = sanitizeChatworkBody_(bodyRaw);
if (userText) {
const answer = ragAnswer_(userText);
sendChatworkMessage_(roomId, answer);
}
}
// Chatworkは200を期待するので必ずok返す
return ContentService.createTextOutput('ok').setMimeType(ContentService.MimeType.TEXT);
} catch (err) {
Logger.log('doPost error: ' + (err.stack || err));
return ContentService.createTextOutput('ok');
}
}
function sanitizeChatworkBody_(body) {
if (!body) return '';
let t = body;
// メンション / 引用タグ
t = t.replace(/\[To:\d+\]/g, ' ');
t = t.replace(/\[rp\s+aid=\d+\s+to=\d+\s+time=\d+\]/g, ' ');
// 余計な囲み
t = t.replace(/^\s+|\s+$/g, '');
// 連続空白整理
t = t.replace(/\s{2,}/g, ' ');
return t.trim();
}
function ragAnswer_(userText) {
// ここで落ちたらエラー文字列を返し、上位でそのまま送信
try {
const qVec = embedTextOpenAI(userText);
const top = searchTopK(qVec, 5); // [{text,score,source,chunk_no}]
const answer = generateWithContextOpenAI(userText, top);
return answer;
} catch (e) {
return '内部エラー: ' + (e.message || String(e)).slice(0, 200);
}
}
解説:コード①で何をしているか
sendChatworkMessage_(roomId, text)
ChatWorkのメッセージ投稿APIを叩くヘルパー。X-ChatWorkTokenを送り、フォームエンコードで{ body }を投げます。HTTP 4xx/5xx は例外化。verifyChatworkSignature_(e, rawBody)
Webhookの署名検証(HMAC-SHA256, Base64)。GASの都合でヘッダが取れない場合があるため、クエリパラメータに署名が無い時は通過(ログ記録あり)。運用方針に応じて使い分け。alreadyHandled_(messageId)
連投防止。message_idを Script Cache に10分保持して同一イベントの多重処理をブロック。isSelfMessage_(ev)
自己ループ防止。CHATWORK_MY_ACCOUNT_IDとev.account_idを突き合わせ、自分の発言は無視。hasToMe_(body)
To必須の実装。本文に[To:MY_ID]が含まれているかチェック(mention_to_meイベントも許可)。doPost(e)
Webhook本体。- 受信JSONを解釈 → 2) To/自己/重複チェック → 3) 本文を整形(
sanitizeChatworkBody_) → 4) RAG本処理(ragAnswer_)→ 5) 返信。最後は常に200で返します。
- 受信JSONを解釈 → 2) To/自己/重複チェック → 3) 本文を整形(
sanitizeChatworkBody_(body)
本文のノイズ除去:[To:xxxx]や引用タグを削除し、空白を整形。ragAnswer_(userText)
RAGの入り口。埋め込み→TopK検索→生成を呼び出し、一連の例外は短いエラーメッセージで上位に返します。
コード②:OpenAI & RAG検索・インデックス構築(改変禁止)
こちらもそのまま貼り付けて使えます。
function openAI_(path, payload) {
const apiKey = PropertiesService.getScriptProperties().getProperty('OPENAI_API_KEY');
const url = 'https://api.openai.com/v1/' + path;
const res = UrlFetchApp.fetch(url, {
method: 'post',
contentType: 'application/json',
headers: { 'Authorization': 'Bearer ' + apiKey },
payload: JSON.stringify(payload),
muteHttpExceptions: true
});
const code = res.getResponseCode();
const text = res.getContentText();
if (code >= 400) throw new Error('OpenAI API error ' + code + ': ' + text);
return JSON.parse(text);
}
// 埋め込み: text-embedding-3-small
function embedTextOpenAI(text) {
const data = openAI_('embeddings', {
model: 'text-embedding-3-small',
input: text
});
return data.data[0].embedding; // [float...]
}
// 生成: gpt-4o-mini(RAG指示を強めに)
function generateWithContextOpenAI(userText, chunks) {
const context = chunks.map((c,i)=>`[${i+1}] ${c.text}`).join('\n');
const system = `あなたは提供された社内ドキュメントのみを根拠に回答するアシスタントです。
- コンテキストに無い事は推測せず「わかりません」と答える
- 事実の根拠として利用した番号を最後に列挙する(例: 出典: [1][3])
- 機密情報や個人情報は要約し、最小限のみ返す`;
const user = `# コンテキスト
${context}
# 質問
${userText}
# 期待する出力
- 箇条書き中心の簡潔な回答
- 必要なら手順/注意点も含める
- 最後に "出典: [番号]" を付与`;
const data = openAI_('chat/completions', {
model: 'gpt-4o-mini',
temperature: 0.2,
messages: [
{ role: 'system', content: system },
{ role: 'user', content: user }
]
});
const text = data.choices?.[0]?.message?.content || 'すみません、生成に失敗しました。';
return text;
}
function testOpenAI() {
const key = PropertiesService.getScriptProperties().getProperty('OPENAI_API_KEY');
if (!key) throw new Error('OPENAI_API_KEY が未設定');
const res = UrlFetchApp.fetch('https://api.openai.com/v1/chat/completions', {
method: 'post',
contentType: 'application/json',
headers: { 'Authorization': 'Bearer ' + key },
payload: JSON.stringify({
model: 'gpt-4o-mini',
messages: [{ role:'user', content:'1行で自己紹介して' }],
temperature: 0
}),
muteHttpExceptions: true
});
Logger.log(res.getResponseCode() + ' ' + res.getContentText());
}
function testEmbedding() {
const key = PropertiesService.getScriptProperties().getProperty('OPENAI_API_KEY');
const res = UrlFetchApp.fetch('https://api.openai.com/v1/embeddings', {
method:'post',
contentType:'application/json',
headers:{ 'Authorization':'Bearer '+key },
payload: JSON.stringify({
model:'text-embedding-3-small',
input:'テストベクトル'
}),
muteHttpExceptions:true
});
Logger.log(res.getResponseCode() + ' ' + res.getContentText());
}
function getSheet_() {
const ss = SpreadsheetApp.openById(PropertiesService.getScriptProperties().getProperty('INDEX_SHEET_ID'));
return ss.getSheetByName('index'); // A:chunk_text, B:vector_json, C:source, D:chunk_no
}
function searchTopK(queryVec, k) {
const sh = getSheet_();
const values = sh.getDataRange().getValues().slice(1);
const scored = [];
for (const row of values) {
try {
const text = row[0];
if (!text) continue;
const vecStr = row[1];
if (!vecStr) continue;
const vec = JSON.parse(vecStr);
if (!Array.isArray(vec) || vec.length === 0) continue;
const score = cosineSimilarity(queryVec, vec);
scored.push({ text, score, source: row[2], chunk_no: row[3] });
} catch (_) {
// 壊れた行はスキップ
}
}
scored.sort((a,b)=>b.score-a.score);
return scored.slice(0, k);
}
function cosineSimilarity(a,b) {
let dot=0, na=0, nb=0;
for (let i=0; i<Math.min(a.length, b.length); i++) {
dot += a[i]*b[i]; na += a[i]*a[i]; nb += b[i]*b[i];
}
return dot / (Math.sqrt(na)*Math.sqrt(nb) + 1e-9);
}
function testIndexSheet() {
const ssId = PropertiesService.getScriptProperties().getProperty('INDEX_SHEET_ID');
if (!ssId) throw new Error('INDEX_SHEET_ID 未設定');
const sh = SpreadsheetApp.openById(ssId).getSheetByName('index');
if (!sh) throw new Error('index シートが無い');
const values = sh.getDataRange().getValues();
Logger.log('rows=' + values.length + ', cols=' + (values[0] ? values[0].length : 0));
Logger.log('header=' + JSON.stringify(values[0]));
}
function buildIndexFromDrive() {
const folderId = PropertiesService.getScriptProperties().getProperty('DRIVE_FOLDER_ID');
const folder = DriveApp.getFolderById(folderId);
const files = folder.getFiles();
const rows = [['chunk_text','vector_json','source','chunk_no']];
while (files.hasNext()) {
const file = files.next();
try {
const text = extractText(file.getId(), file.getMimeType(), file.getName());
if (!text || !text.trim()) {
Logger.log('SKIP(empty text): ' + file.getName() + ' (' + file.getMimeType() + ')');
continue;
}
const chunks = chunkText_(text, 1200);
chunks.forEach((t, i) => {
const vec = embedTextOpenAI(t);
rows.push([t, JSON.stringify(vec), file.getName(), i]);
});
} catch (e) {
Logger.log('SKIP(convert/read failed): ' + file.getName() + ' (' + file.getMimeType() + ') -> ' + e.message);
// スキップして続行
}
}
const sh = getSheet_();
sh.clear();
sh.getRange(1,1,rows.length,rows[0].length).setValues(rows);
}
function ingestOneDocForTest() {
const folderId = PropertiesService.getScriptProperties().getProperty('DRIVE_FOLDER_ID');
if (!folderId) throw new Error('DRIVE_FOLDER_ID 未設定');
const folder = DriveApp.getFolderById(folderId);
const files = folder.getFiles();
if (!files.hasNext()) throw new Error('フォルダ内にファイルが無い');
const file = files.next();
const text = extractText(file.getId(), file.getMimeType(), file.getName());
const chunks = chunkText_(text, 800);
if (!chunks.length) throw new Error('抽出テキストが空(PDFが画像のみ等の可能性): ' + file.getName());
const vec = embedTextOpenAI(chunks[0]);
const ssId = PropertiesService.getScriptProperties().getProperty('INDEX_SHEET_ID');
const ss = SpreadsheetApp.openById(ssId);
const sh = ss.getSheetByName('index') || ss.insertSheet('index');
if (sh.getLastRow() === 0) sh.getRange(1,1,1,4).setValues([['chunk_text','vector_json','source','chunk_no']]);
sh.appendRow([chunks[0], JSON.stringify(vec), file.getName(), 0]);
Logger.log('ingested 1 chunk from: ' + file.getName());
}
function chunkText_(t, size) { const out=[]; for (let i=0;i<t.length;i+=size) out.push(t.slice(i,i+size)); return out; }
// メイン:拡張抽出(形式ごとの分岐&フォールバック)
function extractText(fileId, mimeType, originalName) {
try {
// 1) Googleドキュメントはそのまま
if (mimeType === MimeType.GOOGLE_DOCS) {
return DocumentApp.openById(fileId).getBody().getText();
}
// 2) 素のテキスト系(txt / md)
if (mimeType === 'text/plain' || mimeType === 'text/markdown') {
return DriveApp.getFileById(fileId).getBlob().getDataAsString();
}
// 3) CSV / Googleスプレッドシート
if (mimeType === 'text/csv') {
return extractCsvAsText_(DriveApp.getFileById(fileId).getBlob().getDataAsString());
}
if (mimeType === MimeType.GOOGLE_SHEETS) {
return extractGoogleSheetAsText_(fileId);
}
// 4) WordはGoogleドキュメントへ変換してから読む
if (mimeType === MimeType.MICROSOFT_WORD || mimeType === 'application/msword') {
return extractViaTempGoogleDoc_(fileId, originalName);
}
// 5) PDFは内容次第。まずは変換を試す(失敗多い場合あり)
if (mimeType === MimeType.PDF) {
try {
return extractViaTempGoogleDoc_(fileId, originalName);
} catch (e) {
// フォールバック:そのままテキスト抽出(スキャンPDFは空になりがち)
const txt = DriveApp.getFileById(fileId).getBlob().getDataAsString();
if (txt && txt.trim()) return txt;
throw e; // 本当にダメなら上へ投げる
}
}
// 6) Googleスライド(vnd.google-apps.presentation)は export でテキスト化
if (mimeType === MimeType.GOOGLE_SLIDES) {
const blob = Drive.Files.export(fileId, 'text/plain'); // Advanced Drive API v2 必須
return blob.getDataAsString();
}
// 7) PPTX は変換不可が多い→スキップ推奨(必要なら Slides への変換処理を別途)
if (mimeType === 'application/vnd.openxmlformats-officedocument.presentationml.presentation') {
throw new Error('PPTX は未対応(Slides 変換が安定しないためスキップ): ' + originalName);
}
// 8) その他はフォールバックで blob 文字列(多くは期待薄)
return DriveApp.getFileById(fileId).getBlob().getDataAsString();
} catch (err) {
// ここで呼び出し側に投げる(呼び出し側でスキップ&ログ)
throw new Error('extractText failed for ' + (originalName || fileId) + ' : ' + err.message);
}
}
// Word/PDF を Googleドキュメントに「コピー変換」して読む(成功したら後始末)
function extractViaTempGoogleDoc_(fileId, originalName) {
const tempDocId = convertToGoogleDoc_(fileId, originalName); // 変換トライ
try {
return DocumentApp.openById(tempDocId).getBody().getText();
} finally {
try { DriveApp.getFileById(tempDocId).setTrashed(true); } catch (e) {}
}
}
// 変換ヘルパ(Advanced Drive API v2 必須)
function convertToGoogleDoc_(fileId, originalName) {
const resource = {
title: (originalName || 'converted') + ' (tmp)',
mimeType: 'application/vnd.google-apps.document'
};
// 変換できない形式だと例外(今回これにぶつかっていた)
const copied = Drive.Files.copy(resource, fileId);
return copied.id;
}
// CSV を行テキストへ整形
function extractCsvAsText_(csvString) {
const rows = Utilities.parseCsv(csvString);
return rows.map(r => r.join('\t')).join('\n');
}
// Googleスプレッドシートをテキスト化(先頭シートのみ/必要に応じて拡張)
function extractGoogleSheetAsText_(sheetFileId) {
const ss = SpreadsheetApp.openById(sheetFileId);
const sh = ss.getSheets()[0];
const values = sh.getDataRange().getValues();
return values.map(r => r.join('\t')).join('\n');
}
解説:コード②で何をしているか
OpenAI呼び出し
openAI_(path, payload):OpenAIの共通HTTPクライアント(POST)。APIキーはScript Propertiesから取得し、4xx/5xxは例外に。embedTextOpenAI(text):text-embedding-3-smallで埋め込みベクトルを生成。RAG検索のキーとなる数値配列を返します。generateWithContextOpenAI(userText, chunks):TopKチャンクをコンテキストに付け、gpt-4o-miniで根拠限定の回答を生成(「出典: [番号]」を明記)。testOpenAI()/testEmbedding():OpenAIの疎通確認(ログ出力)。運用前のヘルスチェックに。
シート&検索
getSheet_():インデックス用シートindexを開く(INDEX_SHEET_ID必須)。searchTopK(queryVec, k):indexの全行を読み、コサイン類似度で上位K件を返す。壊れた行は安全にスキップ。cosineSimilarity(a, b):2ベクトルのコサイン類似度を計算(ゼロ除算回避の微小項あり)。testIndexSheet():indexシート存在・行数のログ確認。
インデックス構築
buildIndexFromDrive():DRIVE_FOLDER_ID配下のファイルを一括取り込み → テキスト抽出 → チャンク化(1200字)→ 埋め込み生成 →indexに上書き保存。ingestOneDocForTest():フォルダ内の先頭1ファイルから先頭チャンクだけを追加するスモークテスト。chunkText_(t, size):指定サイズでの等分チャンク化(オーバーラップなし)。
抽出(ファイル形式別)
extractText(fileId, mimeType, originalName):形式に応じて最適な抽出方法を選択。- Google Docs / TXT / MD / CSV / Sheets:それぞれAPIで文字列化
- Word/PDF:一時的にGoogle Docsへ変換して本文抽出(失敗はスキップ)
- Slides:
Drive.Files.export(..., 'text/plain')(要Drive API v2) - PPTX:未対応(明示的に例外)
- その他:Blob→文字列(フォールバック)
extractViaTempGoogleDoc_(...):Word/PDFをDocsにコピー変換し、本文取得後にゴミ箱へ。convertToGoogleDoc_(...):Drive API v2でDocsにコピー変換し、そのIDを返す。extractCsvAsText_()/extractGoogleSheetAsText_():表形式を行TSVとして文字列化(検索の一貫性向上)。
導入・運用のヒント
- To必須:
mention_to_meまたは[To:MY_ID]のときだけ反応 → 誤反応が減ります。 - 連投防止:
message_idを10分キャッシュ(Webhookの重複・再送対策)。 - 自己ループ防止:
CHATWORK_MY_ACCOUNT_IDを設定。 - インデックス再構築:資料更新時は
buildIndexFromDrive()を再実行。 - 精度は文書整備が肝:見出し(H2/H3)、Q/A形式、用語統一、余計な目次やノイズ除去、PDFはテキストベース推奨。
トラブルシューティング
- 返信が来ない:Webアプリの公開範囲/デプロイURLの更新漏れ/Webhook URLの設定を確認。
- 投稿に失敗:
CHATWORK_API_TOKENのアカウントがルーム参加済みか、room_idが正しいか。 - RAGで例外:
indexに壊れたvector_jsonが混入 →searchTopKがスキップしますが、行全体が壊れていると空返却のことも。 - 重い/タイムアウト:PDF多数・巨大文書・OpenAIのレイテンシが原因。将来的には**非同期(即ACK→キュー→後送)**へ発展させると安定。
まとめ — GAS×OpenAIでRAGを自作するポイント
- GAS × OpenAI APIだけでRAGボットを自作できる。ベクトルDBや有料サービスは不要
- Google Driveの資料をインデックス化し、Chatworkで質問するだけでAIが社内ナレッジから回答
- 本記事のコードはTo必須・連投防止・自己ループ防止を備えた実用的な最小構成
- RAGの精度向上はコード調整より文書整備が効く。見出しの整理、Q&A形式、用語統一が重要
- 将来的な拡張:非同期キュー化、OCR対応、ベクトルDB移行、アクセス制御・監査ログなど
「RAGを自作したいが、大がかりなインフラは避けたい」という方に最適な構成です。まずは本記事のコードをコピペして動かし、自社のユースケースに合わせてカスタマイズしてください。

