

はじめに
社内のFAQやマニュアルをAIに答えさせたい。
しかも「社員が普段使っているLINEから質問できる」ようになれば、利用のハードルはぐっと下がります。
この記事では、LINE公式アカウント × Google Apps Script(GAS) × OpenAI を組み合わせて、Drive内の資料を検索して回答する RAG(Retrieval Augmented Generation)ボット を構築した過程を紹介します。
実際に試したコード断片も交えつつ、「読み物+実装ハンドブック」風にまとめました。
先にやること:プロパティ設定 & データ準備(最重要)
RAGボットは プロパティが1つでも欠けると動きません。まず最初にこのチェックリストを埋めてください。
✅ Script Properties(必須項目)
LINE関係のキーはLINEのofficial Account ManagerまたはLINE Developersのサイトで取得してください。
OPEN AIのAPI KEYはAPI プラットフォームで発行してください。
Googleドライブ、スプレッドシートはGoogleアカウントはドライブサイトで作成してください。
| キー名 | 用途 | 例 |
|---|---|---|
LINE_CHANNEL_SECRET | Webhook署名検証(LINE → GAS) | xxxxxxxxxxxxxxxxxxxxxxx |
LINE_CHANNEL_ACCESS_TOKEN | Bot返信(GAS → LINE) | xxxxx...(実際はプレーン文字列で保存) |
OPENAI_API_KEY | OpenAIの埋め込み・生成呼び出し | sk-... |
DRIVE_FOLDER_ID | 取り込み対象のGoogle DriveフォルダID | 1AbCdEf...フォルダのURLにある文字列 |
INDEX_SHEET_ID | インデックス保存用スプレッドシートID | 1AbCdEf...スプレッドシートのURLにある文字列 |
設定場所:GAS エディタ → 右上「歯車」→「スクリプト プロパティ」
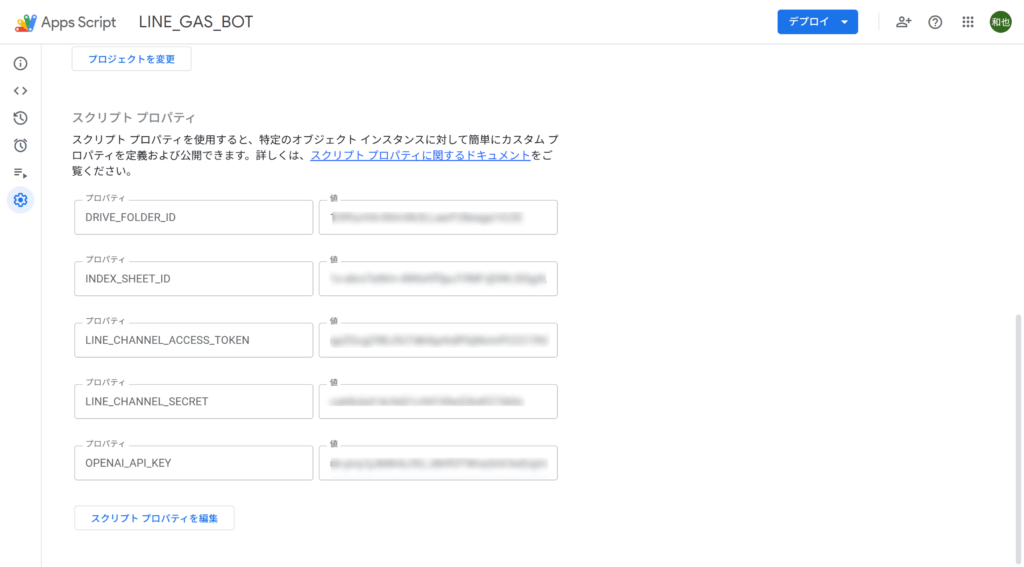
✅ Google側の権限とサービス
- GASのデプロイ
- 「デプロイ → 新しいデプロイ → ウェブアプリ」
- 実行ユーザー=自分 / アクセス権=全員(匿名含む)
- 発行されたURLを LINEのWebhook URL に設定
- Advanced Google Services
- GAS左メニュー「サービス」→ 追加 → Drive API(v2) を有効化
- Google Cloud Console 側でも Drive API が有効化されていることを確認
✅ データ準備(最小構成)
- Driveフォルダ(
DRIVE_FOLDER_ID)に、次のいずれかを入れる- Googleドキュメント、Word(.docx)、PDF(テキストベース推奨)、TXT、CSV、Markdown
- スプレッドシート(
INDEX_SHEET_ID)にindexシートを用意(空でOK)- 初回インデックス時にヘッダを上書きします
PDFがスキャン画像の場合は文字が取れません(OCRが必要)。まずはテキストベース資料でテストしてください。
✅ ワンショット動作確認
最初に sanityCheck() を走らせ、プロパティとAPIキー・I/Oが揃っているか確認します。
function sanityCheck() {
const prop = PropertiesService.getScriptProperties();
const required = ['LINE_CHANNEL_SECRET','LINE_CHANNEL_ACCESS_TOKEN','OPENAI_API_KEY','DRIVE_FOLDER_ID','INDEX_SHEET_ID'];
const missing = required.filter(k => !prop.getProperty(k));
if (missing.length) throw new Error('❌ Missing: ' + missing.join(', '));
Logger.log('✅ Properties OK');
const folder = DriveApp.getFolderById(prop.getProperty('DRIVE_FOLDER_ID'));
if (!folder.getFiles().hasNext()) Logger.log('⚠️ Driveフォルダは空');
const ss = SpreadsheetApp.openById(prop.getProperty('INDEX_SHEET_ID'));
const sh = ss.getSheetByName('index') || ss.insertSheet('index');
if (sh.getLastRow() === 0) sh.getRange(1,1,1,4).setValues([['chunk_text','vector_json','source','chunk_no']]);
Logger.log('✅ indexシートOK');
const res = UrlFetchApp.fetch('https://api.openai.com/v1/chat/completions', {
method:'post', contentType:'application/json',
headers:{ 'Authorization':'Bearer '+prop.getProperty('OPENAI_API_KEY') },
payload: JSON.stringify({ model:'gpt-4o-mini', messages:[{role:'user', content:'OKだけ返して'}], temperature:0 })
});
if (res.getResponseCode() !== 200) throw new Error('❌ OpenAI API error');
Logger.log('✅ OpenAI chat OK');
}

全体像
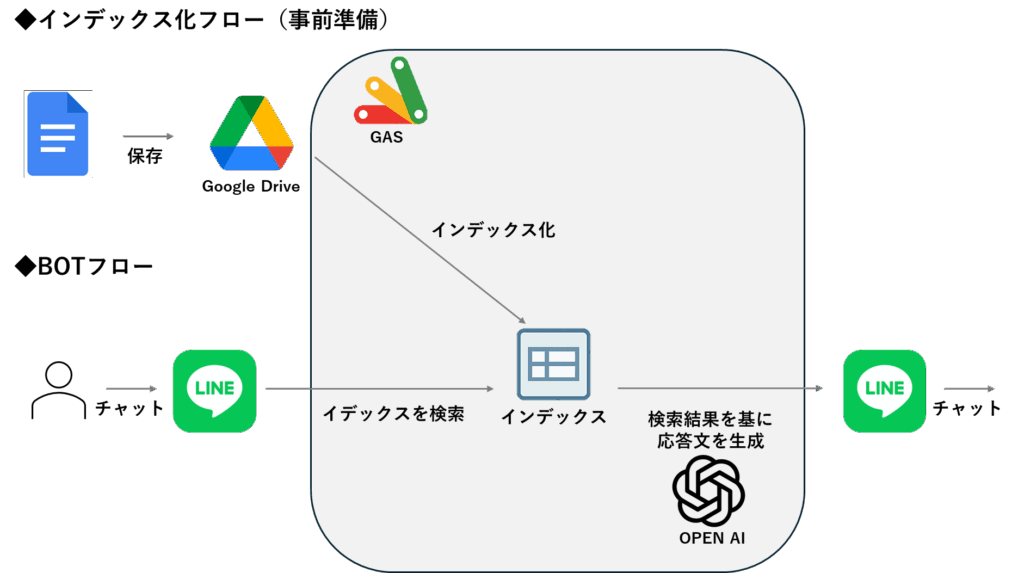
準備ができたら、以下の流れで構築していきます。
- Driveドキュメントをインデックス化(チャンク+埋め込み→シート保存)
- ユーザー質問を検索してコンテキスト取得
- GPTに渡して回答生成
- LINEに返信
ステップ1:エコーボット
まずはLINEとGASのWebhookがつながるか確認。(事前準備チェック)
function doPost(e) {
const body = JSON.parse(e.postData.contents);
const event = body.events[0];
if (event.type === 'message') {
replyMessage(event.replyToken, "エコー: " + event.message.text);
}
}
function replyMessage(token, text) {
const url = 'https://api.line.me/v2/bot/message/reply';
UrlFetchApp.fetch(url, {
method: 'post',
contentType: 'application/json',
headers: { 'Authorization': 'Bearer ' + PropertiesService.getScriptProperties().getProperty('LINE_CHANNEL_ACCESS_TOKEN') },
payload: JSON.stringify({ replyToken: token, messages: [{ type: 'text', text }] })
});
}
これでLINEから送ったメッセージが「エコー: ○○」と返ってくればOK。
ステップ2:ドキュメントのインデックス化
Driveフォルダ内のファイルを読み取り、チャンクに分割して埋め込み→シートに保存します。
抽出関数(抜粋)
function extractText(fileId, mimeType, name) {
if (mimeType === MimeType.GOOGLE_DOCS) return DocumentApp.openById(fileId).getBody().getText();
if (mimeType === 'text/plain') return DriveApp.getFileById(fileId).getBlob().getDataAsString();
if (mimeType === MimeType.MICROSOFT_WORD || mimeType === MimeType.PDF) return extractViaTempGoogleDoc_(fileId, name);
throw new Error("未対応: " + mimeType);
}
チャンク化
function chunkText_(text, size=1200, overlap=200) {
const chunks = [];
for (let i=0; i<text.length; i+=(size-overlap)) {
chunks.push(text.slice(i, i+size));
}
return chunks;
}
インデックス構築
function buildIndexFromDrive() {
const folder = DriveApp.getFolderById(PropertiesService.getScriptProperties().getProperty('DRIVE_FOLDER_ID'));
const files = folder.getFiles();
const rows = [['chunk_text','vector_json','source','chunk_no']];
while (files.hasNext()) {
const f = files.next();
try {
const text = extractText(f.getId(), f.getMimeType(), f.getName());
const chunks = chunkText_(text);
chunks.forEach((c,i)=>{
const vec = embedTextOpenAI(c);
rows.push([c, JSON.stringify(vec), f.getName(), i]);
});
} catch (e) {
Logger.log("SKIP: " + f.getName() + " -> " + e.message);
}
}
const sh = SpreadsheetApp.openById(PropertiesService.getScriptProperties().getProperty('INDEX_SHEET_ID')).getSheetByName('index');
sh.clear();
sh.getRange(1,1,rows.length,rows[0].length).setValues(rows);
}
ステップ3:検索と回答生成
ユーザー質問を埋め込みにして、シート内のチャンクと比較します。
類似度計算
function cosineSimilarity(a,b) {
let dot=0, na=0, nb=0;
for (let i=0; i<a.length; i++) { dot += a[i]*b[i]; na += a[i]*a[i]; nb += b[i]*b[i]; }
return dot / (Math.sqrt(na)*Math.sqrt(nb));
}
応答生成
function generateAnswer(userText, hits) {
const context = hits.map((h,i)=>`[${i+1}] ${h.text}`).join("\n");
const system = "あなたは社内FAQに基づいて回答するアシスタントです。回答は簡潔に、出典番号を最後に示してください。";
const user = `# コンテキスト\n${context}\n\n# ユーザーの質問\n${userText}`;
const key = PropertiesService.getScriptProperties().getProperty('OPENAI_API_KEY');
const res = UrlFetchApp.fetch("https://api.openai.com/v1/chat/completions", {
method:"post", contentType:"application/json",
headers:{ "Authorization":"Bearer "+ key },
payload: JSON.stringify({
model: "gpt-4o-mini", temperature: 0.2,
messages:[{ role:"system", content: system }, { role:"user", content: user }]
})
});
return JSON.parse(res.getContentText()).choices[0].message.content;
}
動作例
Driveに「会社概要」「FAQ」「料金表」を置いて、いったんインデックスを生成。
GASの画面から関数を指定して実行。今回の場合はbuildIndexFromDrive
でLINEから質問。

精度を左右するもの
実装してわかったのは、精度はコードよりドキュメント整備で決まるということ。
- 見出しを正しくつける(H2/H3単位)
- FAQは必ずQ/A形式で
- 用語を統一する
- ページ番号や目次は削除
- PDFはテキストベースで
これを徹底するだけで検索ヒット率が大きく変わります。
チューニングの方向性
コード側でできる工夫もあります。
- チャンクサイズ(小さめ=正確、大きめ=説明力)
- オーバーラップ
- 隣接チャンクを一緒に提示
- プロンプト設計(文体・出典記載など)
ただ、最初に手をつけるべきはやはり ドキュメントの調整 です。
まとめ
- LINE × GAS × OpenAI でDrive資料検索ボットを構築
- インデックスはスプレッドシートで軽量実装
- 精度はコード調整よりもドキュメント整備がカギ
- 運用ルール(ドキュメント登録指示書)を作ると効果大
- 将来的にはベクトルDBやOCRで拡張可能
小さなチームでもすぐに始められる仕組みなので、ぜひ試してみてください。

